Strategy: Test changes systematically
有时候,我们很难判断一个改变——例如,新的指示或新的设计——会使你的系统变得更好还是更差。查看几个示例可能会暗示哪个更好,但是在小样本的情况下,很难区分真正的改进和随机运气。也许这种改变在某些输入上有助于提高性能,但在其他输入上却降低了性能。
评估程序(或”evals”)对于优化系统设计很有用。好的评估应该是:
- 代表真实世界的使用情况(或者至少是多样化的)
- 包含许多测试案例以获得更大的统计能力(请参阅下表以获取指导方针)
- 容易自动化或重复
- 在95%的信心水平下,
检测到的差异 所需要的样本数量:
30% ~10,
10% ~100,
3% ~1000,
1% ~10000
输出的评估可以由计算机、人或两者混合完成。计算机可以用客观标准(例如,只有一个正确答案的问题)以及一些主观或模糊的标准自动化评估,这种情况下模型的输出由其他模型的查询来评估。OpenAI Evals是一个开源软件框架,提供了创建自动化评估的工具。
当存在一系列可能被认为同样高质量的输出时(例如,对于有长答案的问题),基于模型的评估可能会很有用。可以通过模型评估和需要人来评估的边界是模糊的,并且随着模型变得更有能力,这个边界也在不断变化。我们鼓励你进行实验,以了解基于模型的评估对你的用例有多大的效果。
策略:根据金标准答案评估模型输出
假设我们知道问题的正确答案应该引用一组特定的已知事实。那么我们可以使用模型查询来计算答案中包含了多少所需的事实。
例如,使用以下系统消息:

以下是一个例子,其中两点都得到满足:

以下是一个例子,只有一点得到满足:

以下是一个例子,没有一点得到满足:

此类模型评估有许多可能的变体。考虑以下变体,它跟踪候选答案与标准答案之间的重叠种类,并跟踪候选答案是否与标准答案的任何部分相矛盾。

以下是一个例子,答案虽然不符合标准,但并未与专家答案相矛盾:
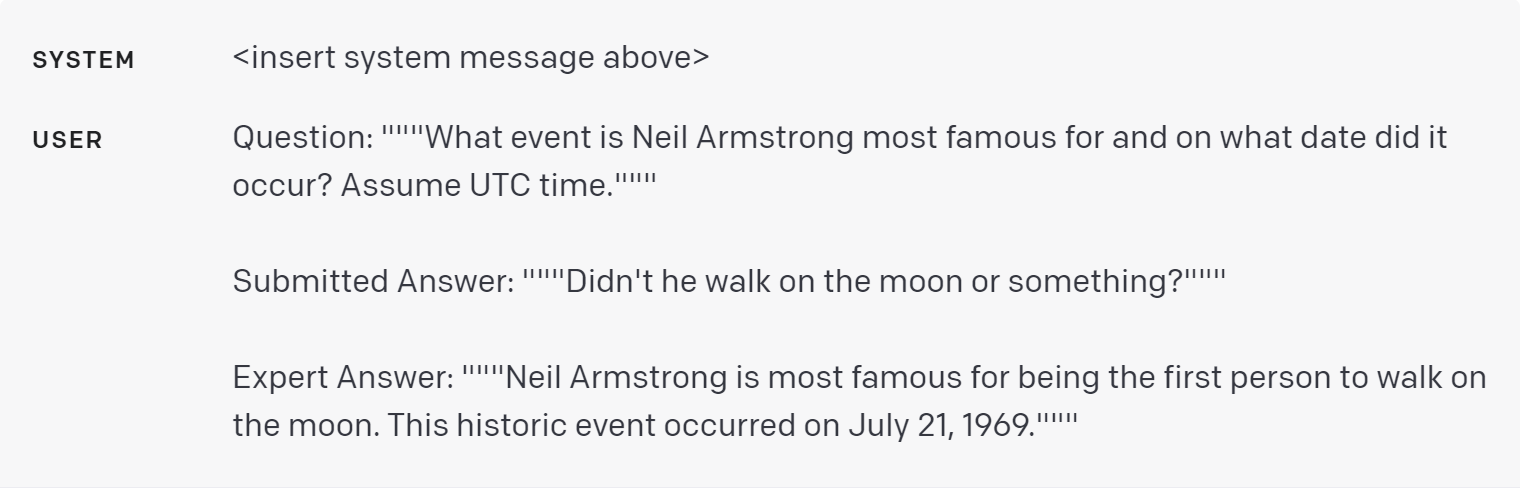
以下是一个例子,答案直接与专家答案相矛盾:
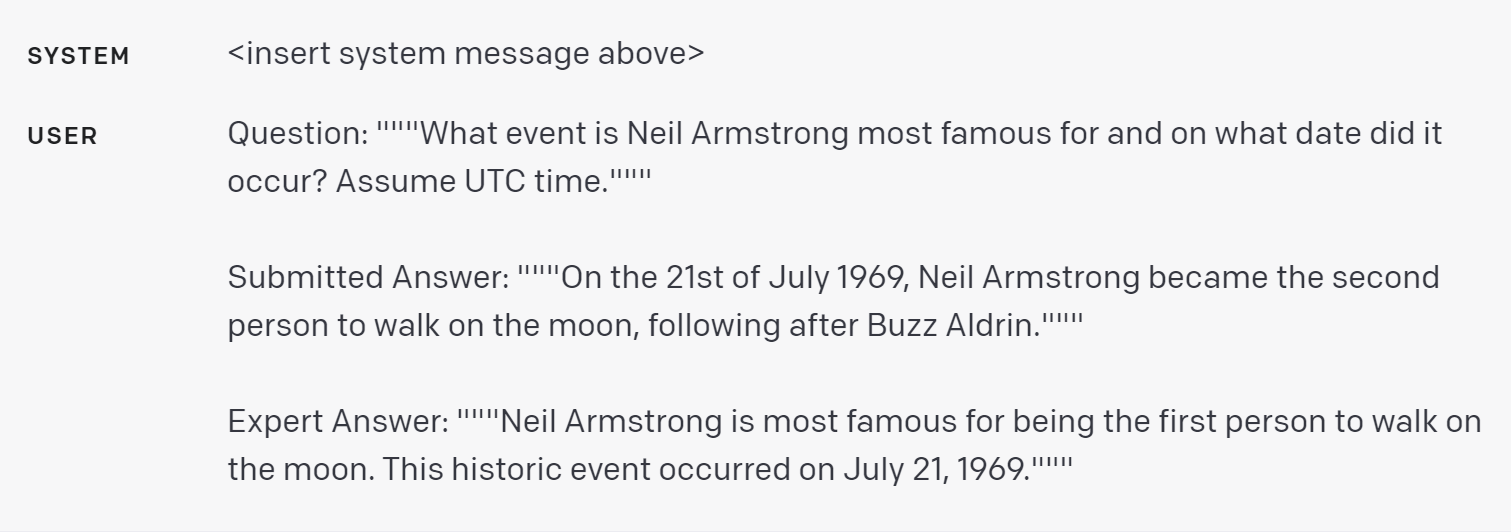
以下是一个例子,答案是正确的,但提供了比必要更多的细节:
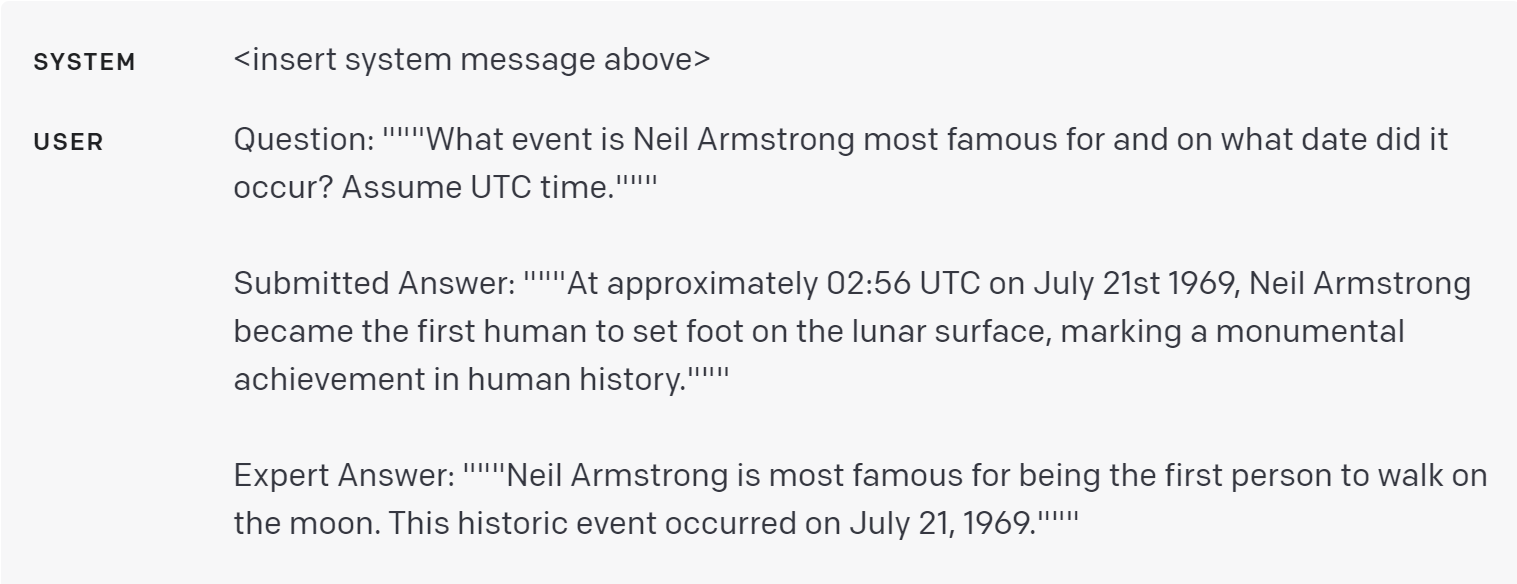
其他资源
想要获取更多的灵感,可以访问OpenAI Cookbook,其中包含示例代码,也链接到第三方资源,例如: